智能計算的基石 服務器軟硬件架構與基礎軟件服務深度解析
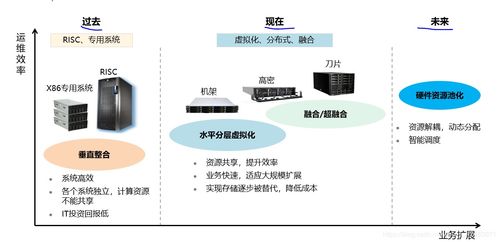
在人工智能與大數據浪潮的推動下,智能計算已成為驅動社會數字化轉型的核心引擎。其效能與穩定性的根基,深植于精心設計的服務器軟硬件架構以及承載其上的基礎軟件服務。本文將系統性地剖析這兩大基石,揭示它們如何共同構建起現代智能計算的高效、可靠運行環境。
一、服務器硬件架構:算力的物理承載
智能計算對算力的渴求是近乎無限的,這直接驅動了服務器硬件架構的持續演進。其核心組件構成了一個高效協同的計算體系:
- 計算核心(CPU/GPU/XPU):中央處理器(CPU)作為通用控制與調度中心,負責復雜邏輯與任務協調。而在智能計算場景中,圖形處理器(GPU)因其大規模并行計算能力,已成為訓練深度學習模型的主力。為特定場景優化的專用處理器(如TPU、NPU等XPU)也在崛起,提供更高的能效比。
- 內存與存儲層次:海量數據的快速存取離不開分層存儲架構。高速緩存(Cache)、大容量內存(DRAM)確保了計算核心的“糧草”供應;而NVMe SSD等高性能固態硬盤,以及分布式存儲系統,則構成了龐大的數據倉庫,滿足模型參數和訓練數據集的高吞吐、低延遲訪問需求。
- 高速互聯網絡:在分布式計算集群中,服務器節點間的通信效率至關重要。InfiniBand、RoCE等高速網絡技術,以及NVLink等GPU間直連技術,極大降低了數據交換與同步的延遲,使得千卡乃至萬卡集群能夠如同一臺巨型計算機般協同工作。
二、服務器軟件架構:資源的智慧調度
硬件能力需要通過軟件才能被充分釋放和靈活組織。服務器軟件架構的核心目標在于實現資源的抽象、池化與智能化調度。
- 虛擬化與容器化:虛擬化技術(如KVM、VMware)將物理服務器抽象為多個邏輯獨立的虛擬機。而容器技術(以Docker為代表)及其編排系統Kubernetes(K8s),則以更輕量、更敏捷的方式封裝應用與依賴,實現了資源的精細化管理和彈性伸縮,成為部署AI微服務的標準范式。
- 資源管理與調度器:YARN、Mesos,以及K8s的調度器,是集群的“大腦”。它們根據任務優先級、資源需求、數據本地性等因素,動態地將計算任務(如Spark作業、AI訓練任務)分配給最合適的硬件資源,最大化集群整體利用率。
- 監控與運維體系:完善的監控系統(如Prometheus、Grafana)實時收集硬件健康狀態、資源使用率、應用性能指標等數據,結合日志系統(如ELK Stack)和告警機制,為系統的穩定、高效運行提供保障,并輔助進行容量規劃與故障預測。
三、基礎軟件服務:智能應用的生命線
在軟硬件架構之上,一系列基礎軟件服務為智能計算應用提供了不可或缺的通用支撐能力,構成了應用開發的“新基建”。
- 分布式文件與對象存儲:如HDFS、Ceph、MinIO等服務,提供了可擴展、高可靠的海量數據存儲能力,是訓練數據的集中管理池。
- 大數據處理框架:Apache Spark、Flink等框架,提供了強大的離線批處理和實時流數據處理能力,是進行數據清洗、特征工程等預處理環節的關鍵工具。
- AI開發框架與平臺:TensorFlow、PyTorch等深度學習框架極大降低了模型研發門檻。而MLflow、Kubeflow等MLOps平臺,則幫助管理模型的全生命周期——從實驗跟蹤、版本控制到自動化訓練、部署與監控。
- 服務網格與API網關:在微服務架構下,Istio等服務網格管理服務間的通信、安全與可觀測性;API網關則作為統一的流量入口,處理路由、認證、限流等策略,保障AI服務接口的穩定與安全。
###
智能計算的宏偉大廈,始于服務器硬件的堅實“地基”,成于服務器軟件的靈活“框架”,最終通過豐富的基礎軟件“設施”賦能千行百業。軟硬件架構的協同優化與基礎服務的持續演進,是釋放算力潛能、降低應用成本、加速智能落地的關鍵。隨著存算一體、CXL互聯、量子計算等新硬件形態,以及Serverless、AI原生架構等新軟件范式的成熟,這一基石將被賦予更強大的智能與更極致的效率,持續推動智能計算邁向新的高度。
如若轉載,請注明出處:http://www.xueyaping.cn/product/49.html
更新時間:2026-03-09 12:53:15